Part 1 disini
OK, now I want to ask you guys…
…kalau ada 3 keyword… Network…IT Risk…dan Pandemi
Apa yang ada dibenak para kisanak sekalian? …ini apa nyambungnya…
(yak, sama…setidaknya untuk low level employee kek kita2)

But here’s why we were wrong, kita akan nyambungin ini semua berdasarkan contoh use case di IT Training Center that I work at (and all-in-one tools for risk assessment, link ada dibawah)
——————
In the last post, saya sudah curhat Tersesat 1.0 … Tersesat 2.0 … Tersesat 3.0
Sekarang kita berada pada point Tersesat… Advanced level version
First, kita bahas Pandemi
Gila jungkir balik mas (turun) beroh
Every business, every person, every nation… semua yang sudah settle dengan bisnis proses-nya masing2, begitu Covid muncul… *BAM* …lalu di tangkap… (*maaf… anak saya masi suka nyanyi cicak di dinding)
Intinya situasi ini bikin RUSAK…merusak tatanan dunia yang sudah ada
Dengan adanya pandemi ini, semua entitas harus puter otak, how to survive… at least sampe 2021 akhir (gue udah pernah ngomong sama temen awal 2020 lalu, ini bisa 2 tahun, and im afraid its true… and not proud of that)
Nah…disini benang merahnya tentang judul diatas
At the moment the pandemic spread, apa yang dipikirkan oleh para business owner??
Yup…2 things, preserving (their) lives… and also saving their ASSETS
Mau ga mau memaksa every person on earth changing how their business works (udah kek anak jaksel belum)
Yaitu customer tetap ingin training (surprisingly a positive thing in this situation, gue kira malah ga ada samsek), but… can you do it without interacting directly?
Kalau dalam CObIT, customer needs harus dimapping ke enterprise needs…so, kebutuhan klien tentang training virtual semakin marak disaat permintaan training offline/tatap muka semakin berkurang…klo ga bisa dibilang ZERO ya (ya kalau ngomongin rejeki mah ya… satu pintu tertutup, yang lain pasti kebuka lah ya)
So, how do we do it? what component should we have and provide?
Salah satu core value dari IT Governance adalah providing value…and according to CObIT this can be achieved by 3 things: Benefit Realization, Resource Optimization, and Risk Optimization
Nah, point of view akan saya fokuskan ke optimisasi (control) resiko, secara nanti kita sambungin dengan network dan nyambung pula ke video tutorial yg ada di channel yutub saya (link dibawah), karena klo ngomongin benefit realization ya udalah ya, ada permintaan training, selama bisa ya hajar aja, asal halal ya embat, dari segi resource di kantor juga mumpuni (dilihat dari sisi infrastruktur, trainer, booklet, and so on) plus ga terlalu gagap dengan training model itu (kita pernah ngadain training data center secara virtual sudah sejak lama, lebih tepatnya…trainernya ga bisa ke Indonesia)
OK… now we have a goal, business goal… in this pandemic situation
Our use case = VIRTUAL CLASSROOM TRAINING
—————
Second, how to do risk (control) optimization correctly
Pertama, identifikasi asset.
Aset mana saja yang mendukung bisnis proses (in this case, online/virtual training), lalu dimapping “dependency” alias ketergantungannya, asset mana yang tergantung ke asset mana, barulah ketemu aset2 kritikal dalam pelaksanaan virtual classroom
Biasanya informasi2 tentang dependency ini di taro di dokumen yang namanya BIA (business impact analysis), dokumen ini juga sangat berguna untuk orang2 yang mengurusi BCP (business continuity planning), itu tu..yang (salah satunya) orang2 yang ngurusin DRC (Disaster Recovery Center), karena didalamnya ada informasi2 penting terkait RTO (recovery time objectives, how fast we can recover) dan RPO (recovery point objectives, how long we can survive)
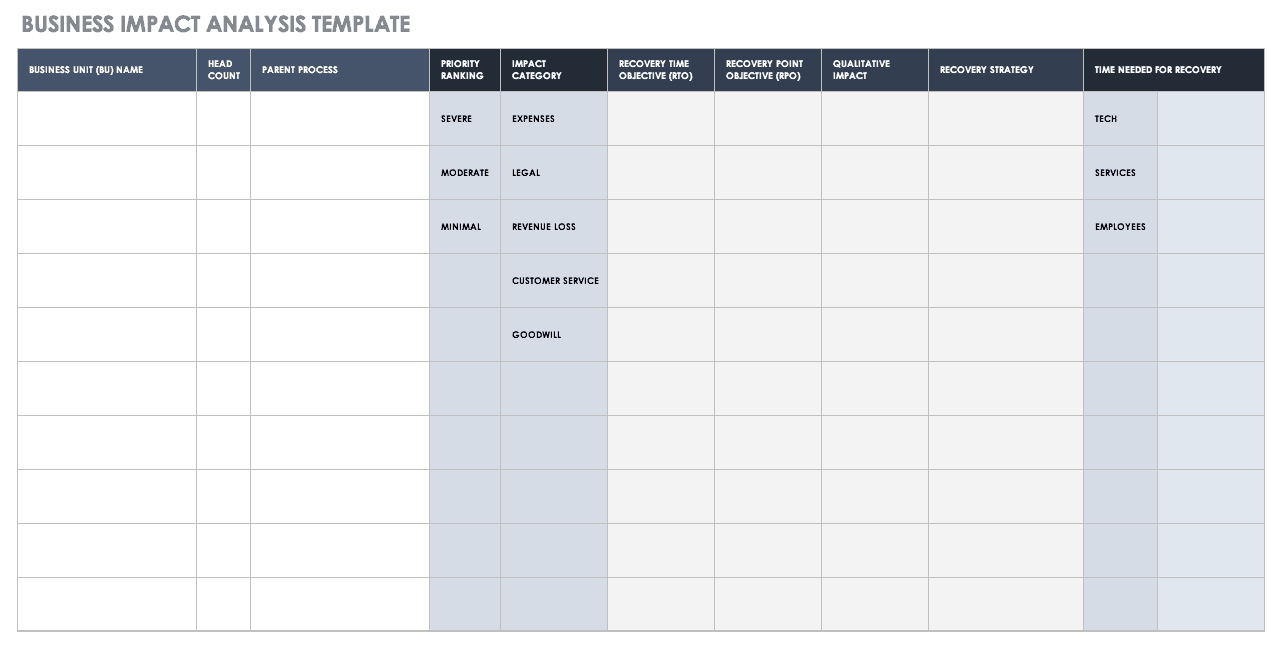
Link gambar diatas ada disini
Nah, according to NIST SP 800-30 tentang guideline untuk asesmen resiko, aset2 tersebut harus kita framing (RISK FRAMING a.k.a RISK CONTEXT), kenapa? Agar kita bisa melihat vector2 atau arah darimana resiko berasal
Dalam kasus virtual training, asset kita apa saja? Pertama…Infrastruktur (Jaringan/Network), Kedua…Instruktur, Ketiga…bahan ajar (softcopy maupun lab material)
Untuk identifikasi aset dari segi infrastruktur, ada 2 tipe training, yaitu manajemen dan teknikal
Untuk yg pertama… arah masalah yang akan muncul atau yang kita biasa bilang threat (defisini threat: event yang punya potensi merugikan) hanya dimasalah koneksi ke virtual room, dari koneksi trainer maupun koneksi peserta.
Untuk koneksi trainer dengan kebijakan WFH yg bisa ngajar dari rumah dalam keadaan koneksi jelek bisa diatasi dengan masuk ke kantor, disana disediakan 1:1 bandwidth allocation dari ISP, sekarang tinggal leftover alias residual risk-nya…yaitu koneksi peserta (biasanya di mitigasi/reduksi dengan cara “diwanti-wanti” koneksi harus bagus atau memakai koneksi dari kantor masing2)
Kan bisa direkam? Bukannya ini jadi salah satu solusi? justru ini Threat selanjutnya
Kita ga ingin rekaman itu bisa di download/replayable untuk peserta (kalau tidak ada ijin dari manajemen), you know lah… jadi menurunkan value trainingnya, bukankah sudah banyak video2 tutorial dari Pluralsight, Lynda, dll?!? Versi “torrent”nya juga banyak beredar di internet… ini salah satu threat. So, giving training record is not so recommended risk response selection, apalagi kalau peserta konek dari kantor, telinga memang dengerin instruktur, tapi mata dan tangan ngerjain kerjaan kantor… apalagi dengan video off dan mic off, entah dimana itu orang2

Lalu untuk yang teknikal… kantor menyulap kelas/ruangan training yg biasa diisi manusia menjadi ruangan yang diisi “hantu”, alias virtual attendee
Contoh untuk kelas Cisco, EC-Council (klo somehow ga bisa iLab), etc. yang membutuhkan bahan ajar seperti lab/praktek… kita menyediakan akses ke ruangan fisik di kantor kita (via teamviewer/anydesk) agar peserta dengan segala keterbatasannya bisa praktek

Challenge nya adalah… belum tentu peserta mengikuti instruksi kita, kita bisa monitoring MONITOR mereka di kelas, adaaa yg gerak…adaaaa yg meneng ae (diem aja), sampai sekarang setiap ada kelas training, kita bikinkan WAG agar bisa koordinasi secara realtime

Disini kantor punya ide bikin satu konsep training “X” (masih digodok oleh R&D), supaya peserta bisa full focus di online training, ibarat kata… “kaki, tangan, dan matanya” ga bisa lepas dari layer yg disuguhkan oleh instruktur, we’ll see what happens in the future about this “X”…mudah2an lancar dan sukses
NAHHH lalu… kita sudah identifikasi asset dan melihat threat2 terhadap asset, ketemulah perkiraan (guessing method, nanti kita bahas dibawah) seberapa sering (chance/likehood) threat ini muncul, lalu impact terhadap bisnis bagaimana, termasuk vulnerability2 kalau kita melakukan apa yang sudah kita rencanakan
Tinggal manajemen dikantor lah yang decide (merekalah RISK OWNER, yg nanggung resiko)…”how much they willing to tolerate the risk” a.k.a risk acceptance, itu tandanya harus ada asesmen
————
Third, Asesmen Resiko
What Risk? Resiko kalau ngadain training secara virtual pastinya
Did it has a risk? How we find it? Makanya asesmen.
How to assess? Ok, look…
Langkah pertama… kita “mapping” Risk Identification-nya dengan cara collecting Audit Report, Vuln. Assessment, Interview (metode ini yang dipilih), Workshop, Seminar, and so on
Kenapa Interview? The easiest one, tapi akurasi dalam identifikasi resiko terbilang rendah (bisa jadi karena bias, underestimate risk yang malah anggep enteng pandemi, atau malah overexaggerate alias parno berlebih)
Any tips on interview? 1. Do research about the problem first (virtual training itu karakteristiknya seperti apa, komponen2 pendukungnya apa), 2. Terjadwal, 3. Pertanyaan2 sudah disiapkan 4. Semua entitas/orang2 yang terkait tentang virtual training ditanyakan (IT staff, sales, marketing, instruktur, dll)
Langkah kedua… choose your assessment analysis method
Ada 2 garis besar dalam risk assessment, Qualitative Analysis vs Quantitative Analysis
Perbedaan:
- Quantitative = using tools, time consuming
- Qualitative = “guessing” method, faster
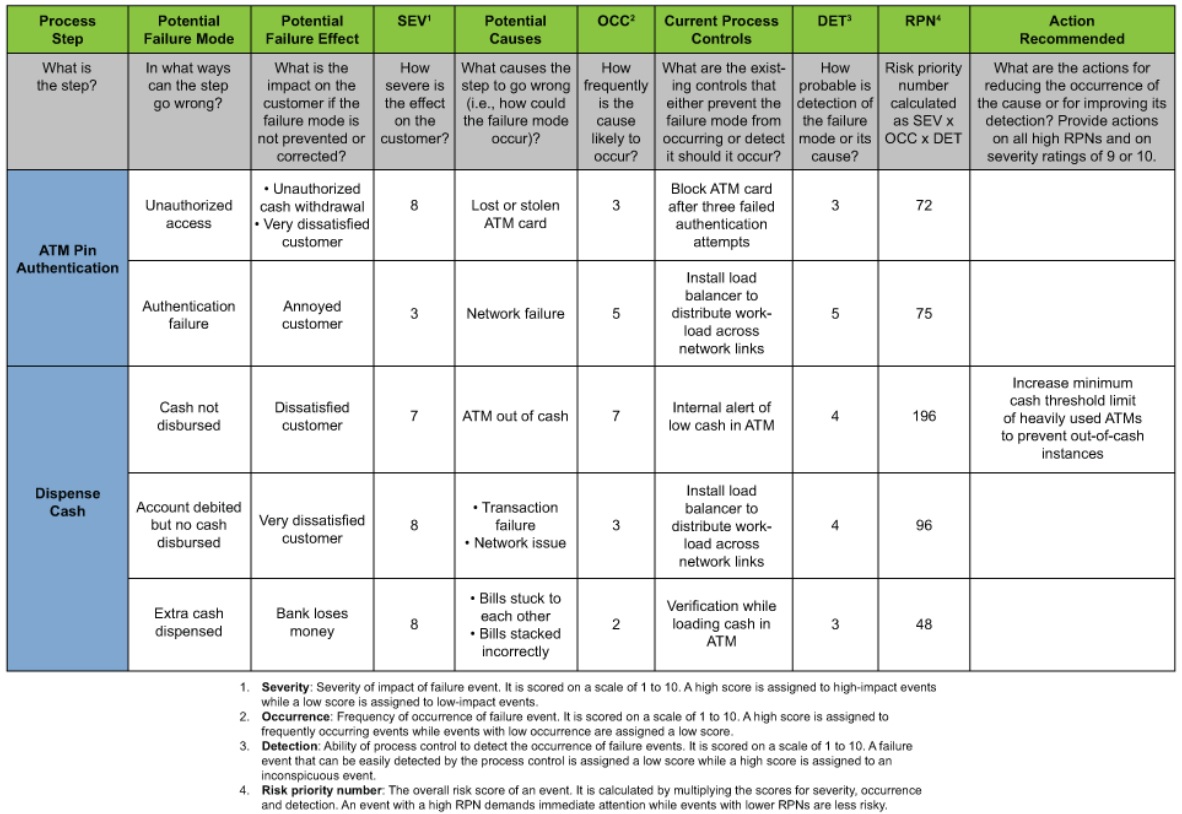
Contoh tools yang sering digunakan dengan Quantitative adalah FMEA (failure modes and effect analysis)
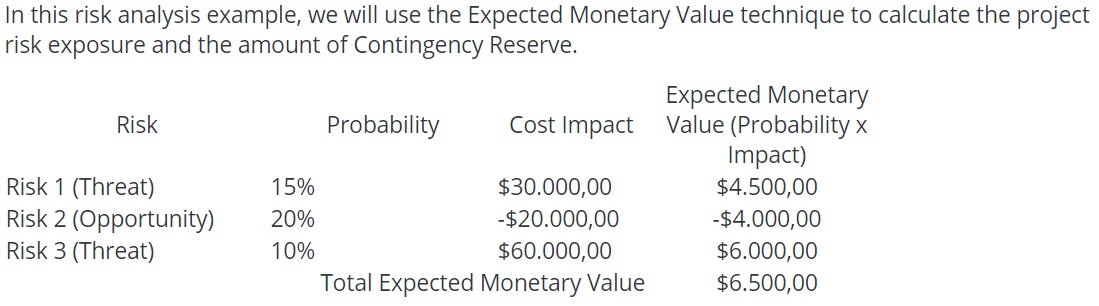
Contoh lain quantitative risk analysis adalah dengan Expected Monetary Value
Lalu ada yang namanya Decision Tree Analysis (googling up yourself) dan…*aha* Monte Carlo Analysis
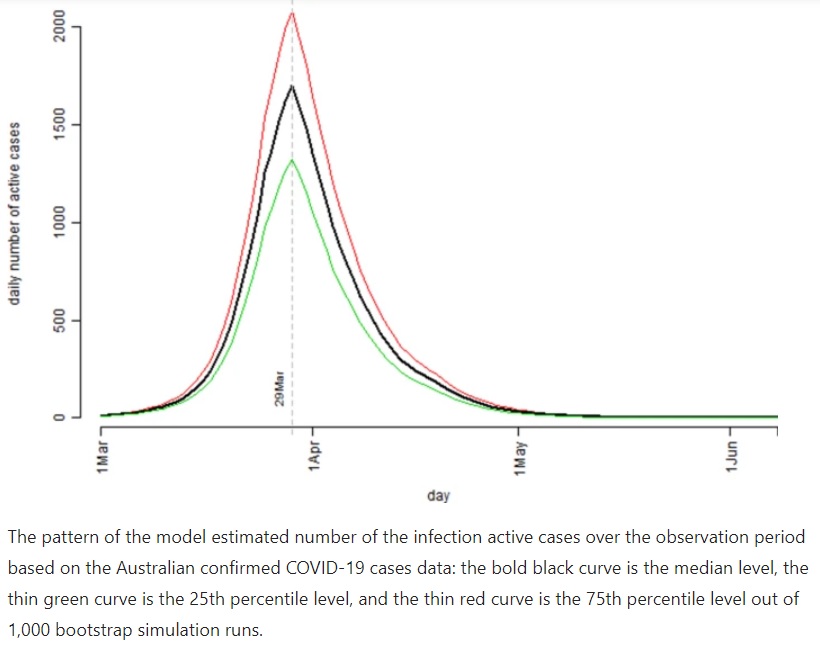
See those pic above? Its monte carlo quantitative risk analysis for COVID-19 in Australia (keknya grafik simulasi penyebaran klo lockdown vs ga lockdown di sosmed juga salah satunya pake monte carlo analisis deh *CMIIW*)
Kalau Qualitative bagaimana? Contohnya adalah Bayesian Analysis (penjelasan tentang ini ada di link video dibawah) dan Brainstorming, kita pake ini…using Delphi Method
Delphi Method? OK, begini… delphi method itu punya proses namanya E-T-E a.k.a Estimate-Talk-Estimate a.k.a Round 1-Discussion-Round 2
Contoh kita pake case yang ada, ketika pandemi muncul, revenue turun drastis… kenapa? How? What happen aya naon?
Ronde pertama (Round 1)… semua stakeholder internal dikumpulin…RAPAT, Isinya pembicaraan tentang kenapa-bagaimana-dan-solusi keluar dari permasalahan yang ada. But heres what makes Delphi method unique, kita semua dikasi selembar kertas, isinya questionaries tentang keadaan tersebut, trus dikumpulkan secara anonymous
Discussion… setelah paper2 (lebih tepatnya ms word sih) itu dikumpulkan, lalu dianalisalah pendapat2 para stakeholder itu dan dipaparkan pada rapat (executive report summary), yang ternyata (pada kasus kita) revenue menurun yang disalahin ya gara2 Covid ini, nahh disini…kita semua para stakeholder di challenge, apakah kesimpulan ini benar, biasanya ada aja yg kritis dan menyangkal (efek dari anonymous collecting), ini saatnya ronde ke 2
Ronde kedua (Round 2)…sama, questionaries…jawaban yang diberikan BIASANYA beda dari yang pertama (adanya changing point of view setelah paparan sebelumnya)…
Summary… kesimpulannya alias long story shortnya…ternyata bukan karena covid, sebelum covid pun emang sudah turun karena beberapa ada salah strategi penjualan (official learning partner point of view, custom IT training material yang tidak sesuai, dll), Covid ini cuma bikin situasi yang ada makin parah aja
Get it?!?
Di NIST SP 800-30 ada sub bab dimana kita bisa combine “best of both worlds” jadi SEMI-QUALITATIVE (long story short…ini tuh kek bikin range/skala, contoh 1-40=low, 41-80=medium, 80-100=critical, jadi nilai quantitative nya ada, “kira-kira” masuk ke range mana ala qualitative juga ada)
Karena kita sudah tau tentang mengidentifikasi resiko (risk identification) serta kita sudah memilih what best for risk assessment for our case, sekarang output risk assessment ini mau diapain?
—————-
Fourth, Setting Risk Criteria and Risk Responses
Difase ini adalah fasenya manajemen dan tata Kelola, karena karakteristik penekanan pertanggungjawaban resiko ada pada ownernya, responsibilities of senior management
Report dari risk assessment ini akan ditaro dalam semacam “risk databases” yang disebut dengan Risk Register
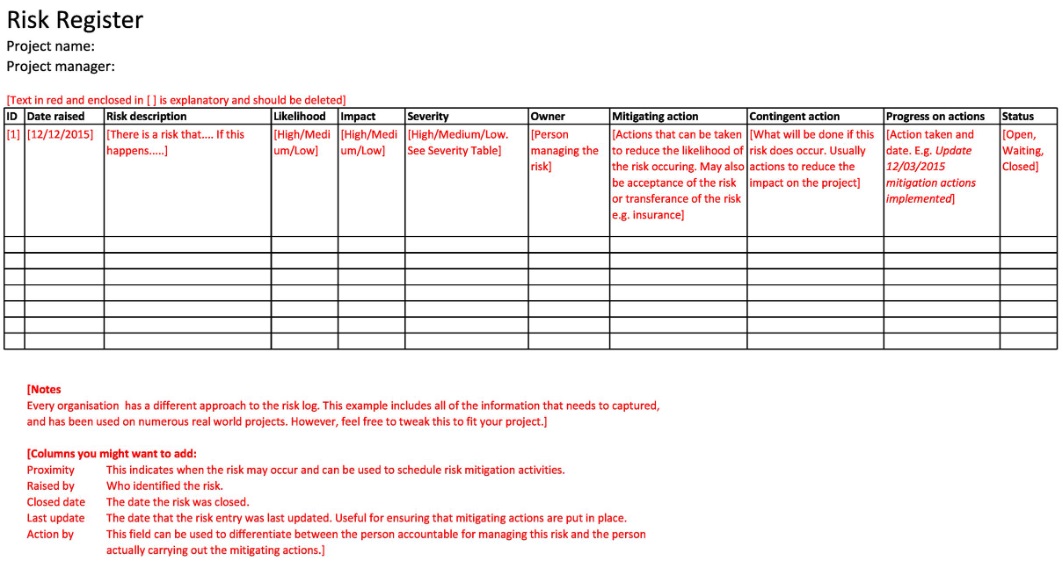
Dari database tersebut, risk management akan membuatkan Risk Assessment Report-RAR (pake powerpoint, excel, atau ms word aja, ilmu infografis lumayan membantu agar senior management get the big picture, untuk dianalisa, mana resiko2 yang akan diprioritaskan untuk di control)
Analisa2 tersebut membutuhkan kriteria, yaitu Risk Criteria, mana saja yang masuk ke low risk, medium risk, atau high risk
Bagaimana cara membuat kriteria resiko? Cara yang paling gampang (yg lebih akurat dari ini sih banyak) adalah Likehood x Impact = Prioritization Criteria, semakin tinggi nilainya, semakin di prioritaskan untuk di control
Dalam kasus Virtual Classroom, kita punya 2 resiko utama
- Internet Putus
- Dokumen/Video/Materi training Bocor
Let’s calculate roughly… internet putus (atau slow) itu chance (likehood)nya dari skala 1-5 (rendah sampai tinggi) adalah 3 (artinya bisa dan agak sering terjadi), tapi dari segi impact nilainya 2 (bisa banyak alternatif koneksi), kalau di kalkulasi berarti 3 x 2 = 6
Sedang Materi bocor, chance-nya mungkin 2, tetapi impactnya besar dengan nilai 4 (competitor knows how to do it, materi bisa di atm-amati tiru modifikasi, weakness dari segi materi dan instruktur keliatan), kalau di kalkulasi berarti 2 x 4 = 8
Artinya, berdasar risk criteria (level) yang menunjukkan bahwa materi (8) lebih di prioritaskan daripada internet (6), kantor memutuskan kita harus membuat semacam mekanisme agar materi otentik dan tidak gampang bocor
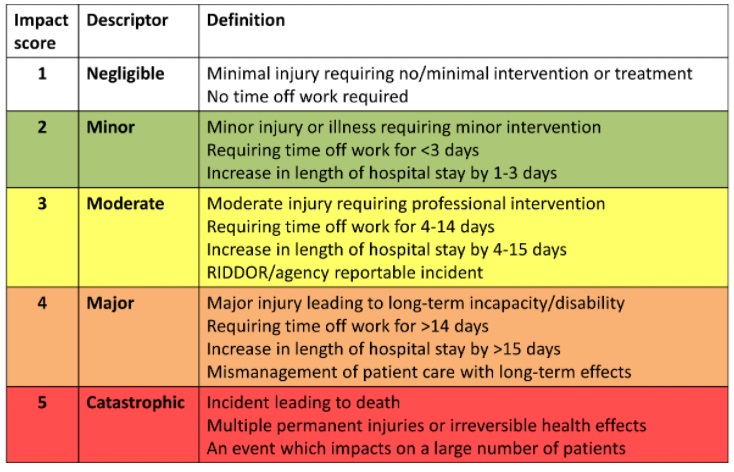
contoh risk level (criteria)
Guideline untuk kriterianya ada di NIST SP 800-30 atau salah satu referensi saya yang lain adalah ssatoolkit.com
KORELASI DENGAN JARINGAN/NETWORKNYA DIMANA? Nah, risk response yang dipilih oleh kantor adalah risk reduction (selecting risk response link vidionya ada dibawah), alias materi2 tersebut disimpan dalam repository LMS (learning management system), some of you already knows moodle (kita sudah pake secara aktif beberapa tahun yang lalu disaat beberapa kampus BARU INTENS makenya sekarang gara2 pandemi…yang mereka banyak curhat, begitu mau dipake, obsolete alias out-of-date gara2 ga pernah diupdate a.k.a dipake….ya kan!??, ya iya lah… dari kacamata mereka, ‘value’ moodle itu belum tinggi waktu itu, makanya dianak-tirikan)
Peran infrastruktur (contoh Network) disini adalah memastikan koneksi ke LMS harus steady dan reliably plus InfoSec view harus diperhatikan (password policy, how to connect, etc.), karena ini jadi CORE BUSINESS FUNCTION kita.
Mulai dari perencanaan redudancy jaringan, genset, failover server LMS, dll diperhatikan semua…karena itu semua asset penting, lebih tepatnya…itu semua adalah aset2 kritikal yang LMS “depends its life” on those aset
Peserta (akses forum, materi, dan vidio), trainer (akses materi, presentasi/pdf/ppt, lab instructions), sales (dokumen report progress peserta before/after training seperti pre-test, post test, exam, etc), dan yang lainnya kan resolve-nya around LMS
Kenapa yang dipilih risk reduction? Kenapa ga yang lain? Karena ga bener2 menghilangkan resiko… ya namanya orang, mau ambil materi ada aja konsep akal bulusnya, file format “.PDC” nya ec-council aja yang secure bisa dibajak, banyak celah menuju roma ya kan?!?!
Sebenernya ada dokumen NIST SP 800-39 tentang manajemen resiko pada information security, isi dokumennya kalau dijabarkan secara singkat adalah… pembagian domain resiko (Organizational Risk, Tactical Risk, Operational Risk), Role2 yang ada dalam menangani resiko, Trust Model, dll… tapi kita ga bahas kesini (kebanyakan)
—–
Nah, terakhir… adalah monitoring, reporting, evaluating, and reviewing risk
Yang namanya jualan, termasuk virtual classroom, pasti butuh evaluasi performa
artinya ada KPI (Key Performance Indicator), yaitu indikator2 tentang seberapa efektif suatu organisasi achieve their goals
Nah karena goal tersebut pasti ada ancaman gagalnya, artinya kita punya KRI (Key Risk Indicator), ya itu indikator apa saja yang bikin organisasi gagal atau terhambat dalam achieving their goals

diatas adalah contoh KRI
kita masih “godok” mau pake measurement kek apa tentang virtual classroom ini
Yah… yang namanya evaluasi dan review, berarti SUDAH DILAKSANAKAN, berhubung data yg bisa di collect baru sedikit, kita ga tau seberapa besar efektifitas dari risk response yg kita pilih
Jadi…. Progressnya akan saya tulis in the next article, ketika sudah memenuhi threshold untuk dianalisa
Tapi so far sih berdasarkan pengamatan pribadi (observation)… adanya peningkatan permintaan dan kesanggupan kita (request fulfilment) dalam melayani permintaan tersebut menunjukkan Virtual Classroom ini headed to the right direction (ini bias? iya, ya namanya juga pengamatan personal)
——
Link
Video tentang Risk Management – Intro
Video tentang Risk Management – Risk Identification
Video tentang Risk Management – Risk Assessment Method
Video tentang Risk Management – Risk Response
Risk Criteria Template
Tool all-in-one from simplerisk.com



