

Setelah masa transisi selesai, saatnya duduk…diam…dan nunggu complain wkwkwk
Pada dasarnya memang Itulah inti dari Service Operation, to make sure the IT services delivered effectively and efficiently
bedain sama Project ya,
Project: Temporary, ada start project, ada stop (closing) project
Operation: Ongoing, terus2an…
jadi klo ada Project “ga kelar2” suka disebut Operation Project hahaha
In a nutshell, Service Operation is about “steady state”
pembahasan service operation berkisar seputar
- Stabilitas vs Responsivitas (stabil tapi lemot, responsive tapi ga stabil)
- Cost vs Quality (ada harga ada rupa bro…)
Ada beberapa proses yang termasuk dalam inti bahasan Service Operation
- Event Management
- Access Management
- Incident and Problem Management (ilmu yang cocok buat IT help desk)
- Request Fulfillment
- IT Operation Control
- Facilities Management
- Application Management
- Technical Management
——————————————–
Event Management
“eh besok garam abis nih…NasGor-nya gimana?”
“tiap jam 12 kok bandwidth kepake lebih dari 80% ya?”
Inti dari Event Management adalah monitoring service dan CI-nya (see Service Transition for CI definition)
Event: semua perubahan keadaan pada CI. Tools untuk ngeliat event adalah SYSLOG Server/Event Viewer/etc.
Tools2 tersebut akan menghasilkan Alerts (notifikasi kek “failure has been occurs”, “threshold warning”, dll)
Di ITIL, ada 3 tipe event yang ditekankan
- Informational Event – logging system, ada user (yang berhak) masuk
- Warning Event – warning sign klo storage udah lebih dari 80% capacity
- Exception Events – lebih ke arah emergency event, CPU heat, malware detection, dll
Ada beberapa bahasan dalam Event Management
- Maintenance of Event Monitoring Mechanism and Rules: mengatur rule2 filter dan set up server untuk event log
- Event Filtering and 1st Level Correlation: mengkategorisasikan mana event yang bisa di ignore dan mana yang harus di tindak lanjuti
- 2nd Level Correlation and Response Selection: menginterpretasikan event dan memilih respon yang tepat untuk event tersebut
-
Event Review and Closure: ya review, mana event yang bisa ditangani mana yang tidak, dari review2 tentang event ini akan menghasilkan Event Trends and Patterns
“eh, tiap jam 12 kok internet lambat ya” “eh, kek-nya tiap 2 minggu garam dapur abis de“
———————————–
Access Management
“siapa yang berhak dapet diskon 50% untuk menu NasGor”
“siapa yang boleh akses VPN ke DaCen”
Inti dari Access Management ya ngasi otorisasi ke user yang berhak mendapat service tersebut
Kadang disebut juga Identity Management atau Rights Management
Isinya berkisar tentang user ID, user Group, profile, LDAP atau ActiveDir, sekitar2 itulah
Ada 2 objektif dari Access Management
- Maintenance of Catalog of User Roles and Access Profiles: bikin katalog/menu tentang user roles dan profiles dan mencegah orang punya akumulasi/beberapa access profile
- Processing of User Access Requests: memproses request untuk add/change/revoke access right dan make sure hanya authorized user yang boleh menggunakan fitur ini
———————————
Incident and Problem Management
“eh, kompor tiba2 mati nih, ga bisa masak NasGor kita”
“kok akses ke DaCen ga bisa ya”
Sebenernya Incident dan Problem Management ini dalam ITIL dipisah sendiri management-nya (Cuma gue gabung, soalnya intinya sama…service kita bermasalah, gimana nanganinnya)
Incident Management: gimana caranya untuk restore Service yang mengalami gangguan performa, secepat mungkin tentunya
Problem Management: menganalisa akar masalah yang menyebabkan incident terulang lagi
Kita perlu tau bedanya Event, Incident, dan Problem…
- Event: segala sesuatu yang berubah pada sistem, kek kita “write mem” untuk save perubahan
- Incident: Event2 yang bersifat negative tapi kita tau penyebabnya dan cara koreksinya, kek “duplicate IP has been detected”
- Problem: Incident yang berulang/belum diketahui penyebabnya dan koreksinya seperti apa, contohnya…Internet mati, tapi ISP bilang ga ada yang bermasalah
Incident Management proses:
- Incident Management Support: tujuannya untuk provide dan maintain tools, proses, skill, dan rules yang dibutuhkan klo ada incident
-
Incident Logging and Categorization: setiap incident harus di record/catet dan memilih incident mana yang harus diprioritaskan untuk dibenerin terlebih dahulu
- Prioritization: Urgency + Impact
- Immediate Incident Resolution by 1st Level Support: solving incident dalam rentang waktu yang disetujui (secepat mungkin intinya), siapa ini? Biasanya Help Desk/Service Desk
- Incident Resolution by 2nd Level Support: klo 1st level support ga bisa solving, workaround-nya gimana. Siapa ini? Biasanya IT Spesialis-nya…netAdmin, sysadmin, dll
-
Handling Major Incidents: ini 3rd Level support yang handle
- 3rd Level Support: biasanya dilimpahin ke vendor/TAC/specialist consultant/3rd party supplier..intinya yg udah expert
- Incident Monitoring and Escalation: monitoring incident secara terus-menerus jadi begitu ada counter-measure terhadap incident langsung bisa di benerin saat itu juga
- Incident Closure and Evaluation: menutup case dari incident yang sudah selesai dan mengevaluasi Incident Record (berkas incident), biar ga kejadian lagi
-
Pro-Active User Information: inform semua pengguna service yang kena incident (tugasnya help desk), jadi user bisa “memposisikan” diri saat incident berlangsung (biar ga banyak email complain masuk, udah dikasi tau duluan soalnya)
- Sistem IT yang sudah mapan biasanya dibikinin User FAQ (biar user ga nanya2 mulu, tinggal liat FAQ-nya di file, dokumen, atau website-nya)
- Incident Management Reporting: pastikan berkas2 incident ini bisa dipake untuk improvement service berikutnya
Fase Incident Management (taken from pearsonitcertification.com)
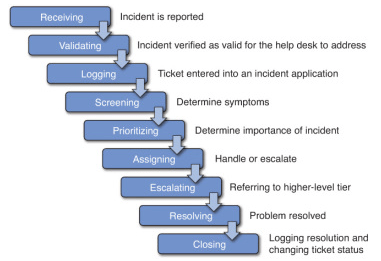
Pencarian solusi terhadap incident yang belum ketemu penyebabnya sehingga harus menunggu incident terulang lagi (agar lebih clear akar masalahnya) disebut Reactive Problem Identification (slow response solution, but providing the best solution)
Untuk Problem Management, ada 7 proses yang dibahas
- Proactive Problem Identification: gimana caranya kita memprovide workaround sebelum incident terulang lagi, fast solution (belum tentu best solution)
- Problem Categorization and Prioritization: sama seperti incident categorization
-
Problem Diagnosis and Resolution: mendiagnosa suatu problem, with RCA
- RCA: Root Cause Analysis, kita bahas detail dibawah
- Problem and Error Control: monitoring problem yang urgent, klo ada tindakan korektif bisa langsung diaplikasikan
- Problem Closure and Evaluation: bikin problem record/catatan dokumentasi problem yang disebut Known Error Database (KEDB), database tentang semua error yang diketahui penyebabnya dan cara mengatasinya
- Major Problem Review: solusi2 dari problem itu di review kembali, kali aja ada yg lebih bagus
- Problem Management Reporting: sama seperti incident management reporting
tadi kita sedikit menyinggung soal RCA, apa sih yang dibahas di RCA?!?
RCA (Root Cause Analysis) itu punya 5 step proses
- Define the Problem (what happen? Gejala2nya apa?)
- Collect Data (how long it happens? What proof? What impact?)
-
Identify Possible Cause (what sequence lead to this? What condition this occurred?)
- so what? Mungkin gara2 budget cut, mungkin skill IT-nya kurang, mungkin…
- why? Kenapa harus 1Gb storage?, kenapa harus pake VPN, kenapa…gara2 itu mungkin
- drilling down…cari semua informasi secara intensif (tentunya yang relevan)
-
bikin diagram Cause and Effect, kek dibawah ini (taken from mindtools.com)
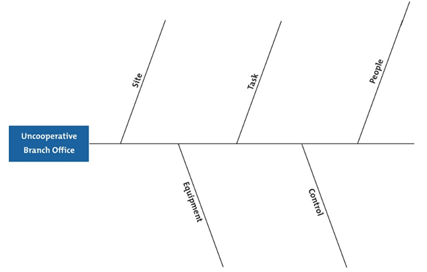
jadi begini…
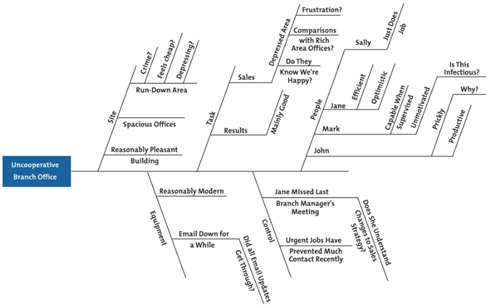
- so what? Mungkin gara2 budget cut, mungkin skill IT-nya kurang, mungkin…
- Identify Root Cause (why this cause exist)
- Recommend and Implement Solutions (what can you do to prevent from happening again)
Untuk meminimalisir RCA, kita bisa pake metode Failure Mode and Effect Analysis (FMEA) atau bahkan pake Kaizen Method
-
FMEA: di desain oleh DoD tahun 1949, yaitu metode analisis resiko untuk QC, di ITIL ini dibahasnya pada Service Design
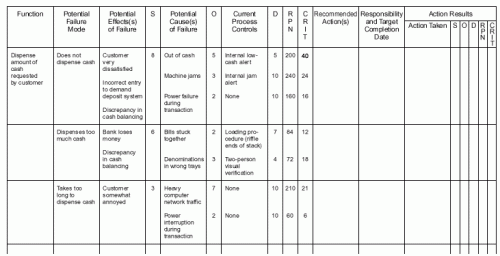
- Kaizen Method: metode ini lebih kearah filosofi (people oriented) daripada sekedar tools. It relies heavily on Continuous Service Improvement phase (link artikel menyusul)
————————————-
Request Fulfillment
“ada yang request NasGor-nya ga pake acar nih, satu lagi minta NasGor aga pedesan dikit”
“ada yang minta dibikinin user account buat akses DaCen via VPN”
Inti dari Request Fulfillment adalah bagaimana kita sebagai service provider bisa menyanggupi atau tidak sebuah permintaan (biasanya yang ringan2/minor request), artinya bikin kanal/bikin tim tempat “penampungan” request service tersebut
bahasa mudahnya… harus ada CASHIER/kasir wkwkwkwk
Jadi klo ada user mau minta hak akses VPN, dia harus bikin/minta Request for Service document
Request fulfillment biasa dihandle oleh Service Desk
Ada 5 proses (ada tambahan di ITILv3 2011) dalam Request Fulfillment
- Request Fulfillment Support: menyediakan tools2, proses, skill yang dibutuhkan buat handling request
- Request Logging and Categorization: mengkategorisasikan request yang masuk, jadi bisa menentukan mana yang mau dikerjain duluan
- Request Model Execution: memastikan request yang dikerjain sesuai dengan time schedule
- Request Monitoring and Escalation: monitoring request2 yang belum dikerjain, mesti diapain ni request
- Request Closure and Evaluation: mengevaluasi request record/catatan2 request yang ada sebelum request tadi dinyatakan selesai/done, berguna juga klo mau improvement service kedepannya dengan melihat request trend
—————————–
IT Operation Control, Facilities Management, Technical Management, dan Application Management
“saatnya kita bentuk tim untuk café, tim Koki/tim dapur, tim managemen keuangan, tim Barista”
“yang ngurus complain DaCen ada tim sendiri, yang ngurus tshoot ada sendiri, yang review request ada sendiri”
Inti dari IT Ops Control, Facilities, Technical, dan Application Management adalah untuk monitoring IT services dan semua infrastructure yang menunjang service itu berjalan, dengan cara…bikin TEAM
Di ITIL team, group, atau organisasi yang ngurus hal tertentu dari proses disebut FUNCTION
Yang paling dibahas di ITIL adalah Service Desk (the 1st Level Support), ada bbrp tipe Service Desk menurut ITIL:
- Local Service Desk: ini yang umum, itu TS (technical support)-nya tempatnya deketan ama user. Jeleknya dari tipe ini adalah kadang requestnya by person…ga pake trouble ticketing dulu, mintanya cepet wkwkw
- Centralized Service Desk: itu TS/help desk di kumpulin di satu ruangan sendiri (kek mirip call center gitu)
- Virtual Service Desk: kek Centralized, Cuma lokasi engga ditempat yang sama
- Follow The Sun: ini yang diterapin di vendor2 gede, tempat call center-nya dimana2 diseluruh dunia /distributed call center…jadi klo lo telpon help desk-nya malem di Amerika, yang jawab dari Call Center-nya India yang masi pagi…, klo lo telpon-nya malem dari Indonesia, yang jawab dari Eropa (yg masi pagi juga)
“good morning, may I help you?”
“(dalem hati)…gue bukannya telpon jam 12 malem nih, ini gue yang bingung apa Die yang dongo sih?”
…jadi, selalu greeting-nya Good Morning…dimanapun elo berada
and next…we’ll talk about ITIL CSI (Continous Service Improvement)
——————————
References:
http://www.pmchamp.com/3-things-you-need-to-know-about-projects-and-operations/
http://wiki.en.it-processmaps.com/index.php/ITIL_Service_Operation
http://www.pearsonitcertification.com/articles/article.aspx?p=2260779&seqNum=7
https://www.mindtools.com/pages/article/newTMC_80.htm
http://asq.org/learn-about-quality/process-analysis-tools/overview/fmea.html
http://www.valuebasedmanagement.net/methods_kaizen.html
http://www.myitstudy.com/blog/2013/04/types-of-service-desk-in-itil/
